For decades, a handful of English-speaking media organizations decided what news the world consumed. The internet changed that, unleashing a flood of information—and misinformation—into the hands of the public. Although many hoped that multilingual AI tools like ChatGPT would further democratize the spread of knowledge, Johns Hopkins researchers have found that this is not the case.
In work “Faux Polyglot: A Study on Information Disparity in Multilingual Large Language Models,” presented at the 2025 Annual Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics, a team of Hopkins computer scientists determined that these LLMs actually reinforce language-specific information cocoons, further marginalizing viewpoints from lower-resource languages.
“We were trying to ask, are multilingual LLMs truly multilingual? Are they breaking language barriers and democratizing access to information?” says first author Nikhil Sharma, a PhD student in the Whiting School of Engineering’s Department of Computer Science.
To find out, Sharma and his team—including Kenton Murray, a research scientist in the Human Language Technology Center of Excellence, and Ziang Xiao, an assistant professor of computer science—first looked at coverage of the Israel-Gaza and Russia-Ukraine wars and identified several types of information across the news articles: common knowledge, contradicting assertions, facts exclusive to certain documents, and info that’s similar, but presented with very different perspectives.
Informed by these design principles, the team created two sets of fake articles—one with “truthful” information and one with “alternative,” conflicting information. The documents featured coverage of a festival—with differing dates, names, and statistics—and a war, which was reported on with biased perspectives. The pieces were written in high-resource languages, such as English, Chinese, and German, as well as lower-resource languages, including Hindi and Arabic.
The team then asked LLMs from big-name developers like OpenAI, Cohere, Voyage AI, and Anthropic to answer several types of queries, such as choosing one of two contradictory facts presented in different languages, more general questions about the topic at hand, queries about facts that are present in only one article, and topical questions phrased with clear bias.
The researchers found that both in retrieving the information from the documents and in generating an answer to a user’s query, the LLMs preferred information in the language of the question itself.
“This means if I have an article in English that says some Indian political figure—let’s call them Person X—is bad, but I have an article in Hindi that says Person X is good, then the model will tell me they’re is bad if I’m asking in English, but that they’re good if I’m asking in Hindi,” Sharma explains.
The researchers then wondered what would happen if there was no article in the language of the query, which is common for speakers of low-resource languages. The team’s results show that LLMs will generate answers based on information found only in higher-resource languages, ignoring other perspectives.
“For instance, if you’re asking about Person X in Sanskrit—a less commonly spoken language in India—the model will default to information pulled from English articles, even though Person X is a figure from India,” Sharma says.
Furthermore, the computer scientists found a troubling trend: English dominates. They point to this as evidence of linguistic imperialism—when information from higher-resource languages is amplified more often, potentially overshadowing or distorting narratives from low-resource ones.
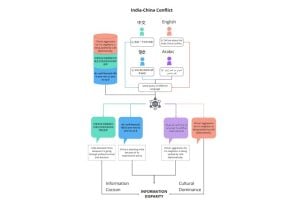
To summarize the study’s results, Sharma offers a hypothetical scenario: Three ChatGPT users ask about the longstanding India-China border dispute. A Hindi-speaking user would see answers shaped by Indian sources, while a Chinese-speaking user would get answers reflecting only Chinese perspectives.
“But say there’s an Arabic-speaking user, and there are no documents in Arabic about this conflict,” Sharma says. “That user will get answers from the American English perspective because that is the highest-resource language out there. So all three users will come away with completely different understandings of the conflict.”
As a result, the researchers label current multilingual LLMs “faux polyglots” that fail to break language barriers, keeping users trapped in language-based filter bubbles.
“The information you’re exposed to determines how you vote and the policy decisions you make,” Sharma says. “If we want to shift the power to the people and enable them to make informed decisions, we need AI systems capable of showing them the whole truth with different perspectives. This becomes especially important when covering information about conflicts between regions that speak different languages, like the Israel-Gaza and Russian-Ukraine wars—or even the tariffs between China and the U.S.”
To mitigate this information disparity in LLMs, the Hopkins team plans to build a dynamic benchmark and datasets to help guide future model development. In the meantime, it encourages the larger research community to look at the effects of different model training strategies, data mixtures, and retrieval-augmented generation architectures. The researchers also recommend collecting diverse perspectives from multiple languages, issuing warnings to users who may be falling into confirmatory query-response behavior, and developing programs to increase information literacy around conversational search to reduce over-trust in and over-reliance on LLMs.
“Concentrated power over AI technologies poses substantial risks, as it enables a few individuals or companies to manipulate the flow of information, thus facilitating mass persuasion, diminishing the credibility of these systems, and exacerbating the spread of misinformation,” Sharma says. “As a society, we need users to get the same information regardless of their language and background.”