Johns Hopkins researchers are using machine learning, or ML, to develop intelligent systems for optimizing and individualizing patient care. By leveraging past data, they are enabling researchers to save time, money, and resources while maintaining the rigorous safety standards required for using ML in medical practice.
Learning from the past
A multi-institutional research team including John C. Malone Associate Professor of Computer Science Suchi Saria has demonstrated how AI and ML can optimize therapy selection and dosing for septic shock—a life-threatening complication that is the leading cause of hospital deaths. The team’s results appear in The Journal of the American Medical Association.
Accounting for more than 270,000 U.S. deaths annually, sepsis often causes low blood pressure that may result in life-threatening organ dysfunction. Emergency treatment includes administering fluids and various vasopressors, or agents that constrict the blood vessels, to raise the patient’s blood pressure to normal levels and restore the flow of blood and oxygen to their organs.
“How best to individualize blood pressure treatment with different therapies remains a complicated open challenge,” says senior author Romain Pirracchio, the Ronald D. Miller Distinguished Professor of Anesthesia and Perioperative Care at the University of California, San Francisco.
International guidelines recommend using norepinephrine, a medication designed to raise blood pressure, before moving on to vasopressin, a blood pressure-raising hormone, if a patient’s blood pressure remains too low. However, septic shock is a condition that changes rapidly and continuously, complicating the decision on whether and when to start vasopressin. What’s more, vasopressin is extremely potent—meaning that starting it too early can cause severe side effects.
“To find the optimal time to begin administering vasopressin, traditionally we’d posit very specific criteria and run a clinical trial—costing millions of dollars and lasting years—comparing those criteria against the standard of care. But this only allows us to test one criterion at a time,” says Saria. “Turns out, there’s a much better way: using reinforcement learning.”
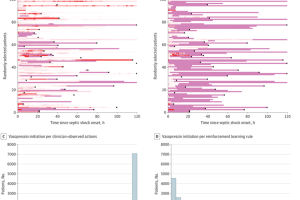
Reinforcement learning, or RL, is a branch of ML in which a virtual agent learns from trial and error to maximize the probability of a good outcome. Using electronic medical records from over 3,500 patients across various hospitals and public datasets, the research team trained an RL model to consider individuals’ blood pressure, organ dysfunction scores, and other medications being taken to determine when to begin vasopressin.
The researchers then validated their model on unseen data from nearly 11,000 additional patients to confirm the algorithm’s effectiveness and verify that deployment would have reduced in-hospital mortality.
“There was a substantial number of patients who were started on vasopressin exactly when our algorithm would have recommended it if it had been live,” says Pirracchio. “So, using complex statistical methods to account for bias and differences in baselines, we were able to show that treatment matching with exactly what the algorithm suggested—in other words, starting at the exact right time—was consistently associated with a better outcome in terms of mortality.”
The model consistently recommended starting vasopressin earlier than most physicians did in practice, but in the few cases where the drug was administered even earlier than the algorithm recommended, patient outcomes were worse.
“This shows that there’s virtue in trying to individualize the strategy to each patient,” Pirracchio says. “There’s no one-size-fits-all rule—in septic shock, there is substantial variability in resuscitation practices between hospitals and in different countries, especially regarding vasopressor support. Given the diversity of the population included in this study, the results show that an individualized vasopressin initiation rule can improve the outcome of patients with septic shock.”
The next step will be to implement the model in practice, going “from promise to reality,” as Saria puts it.
Pirracchio and his team will be doing just that at the UCSF Medical Center before scaling to centers nationally in partnership with Bayesian Health, a clinical AI platform spun out of Saria’s research. But the applications of reinforcement learning in health care don’t stop with vasopressor administration.
“With this kind of infrastructure, instead of doing three experiments at a time, we’re doing a thousand experiments at a time—but we’re not even doing experiments; we’re learning from existing data,” Saria says. “It’s almost like the experiment was already done, for free, and we just get to learn from it and intelligently discover the precise contexts in which different strategies should be implemented to improve patient outcomes and save lives.
“There are lots of opportunities here for reinforcement learning; this is only the start.”
More bang for your buck
Two Johns Hopkins computer scientists have created a solution to one of healthcare AI’s biggest challenges: designing clinical trials that can assess not just current machine learning models, but future versions of those tools.
Michael Oberst, an assistant professor of computer science, and CS PhD student Jacob M. Chen presented their method, which allows one clinical trial to evaluate multiple generations of an AI tool, as an oral presentation—a distinction offered to only 9% of accepted papers—at the 41st Conference on Uncertainty in Artificial Intelligence.
“Without deploying a new ML model in practice, we simply don’t know what would happen,” says Oberst. “Our goal was to estimate the possible outcomes that this new model could have by using the data collected from the previous deployment of a similar model.”
Making limited assumptions to account for whether doctors trust AI alerts and whether results would generalize across patient populations, the Hopkins team validated its framework with a medical alert simulation, showing that it’s possible to evaluate new model versions in this way.
Based on this framework, the team recommends that future ML researchers run trials that test multiple versions of AI tools at the same time, with each version assigned to a different group of users, rather than just randomizing whether or not they get to use an ML model at all.
“This kind of trial design modification will create richer data on which to evaluate new model updates, allowing stakeholders to at least receive some z4ewof an updated model’s worst- and best-case performances before deploying it,” Chen says.
He and Oberst are currently exploring ways to make their method even more precise and are working with collaborators to validate its use on real-world data. Although their approach still requires clinical trials to be conducted—rather than relying solely on observational data—they say this isn’t necessarily a bad thing, as it ultimately allows for greater confidence in a model’s predictions.
“Our hope is that our trial design recommendations will save practitioners time and resources while allowing for quicker deployments of updates to ML models,” says Oberst.