In high-stakes situations like health care—or weeknight Jeopardy!—it can be safer to say “I don’t know” than to answer incorrectly. Doctors, game show contestants, and standardized test-takers understand this, but most AI applications still prefer to give a potentially wrong answer rather than admit uncertainty.
Johns Hopkins computer scientists think they have a solution: a new method that allows AI models to spend more time thinking through problems and uses a confidence score to determine when the AI should say “I don’t know” rather than risking a wrong answer—crucial for high-stakes domains like medicine, law, or engineering.
The research team will present “Is That Your Final Answer? Test-Time Scaling Improves Selective Question Answering” at the 63rd Annual Meeting of the Association for Computational Linguistics, to be held July 27 through August 1 in Vienna, Austria.
“It all started when we saw that cutting-edge large language models spend more time thinking to solve harder problems. So we wondered—can this additional thinking time also help these models determine whether or not a problem has been solved correctly so they can report that back to the user?” says first author William Jurayj, a PhD student studying computer science who is affiliated with the Whiting School of Engineering’s Center for Language and Speech Processing.
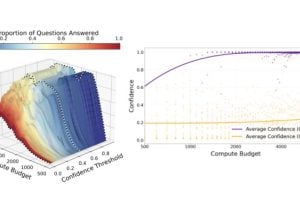
To investigate, the team had LLMs generate reasoning chains of different lengths as they answered difficult math problems and then measured how the chain length affected both the model’s final answer and its confidence in it. The researchers had the models answer only when their confidence exceeded a given threshold—meaning “I don’t know” was an acceptable response.
They found that thinking more generally improves models’ accuracy and confidence. But even with plenty of time to consider, models can still make wild guesses or give wrong answers, especially without penalties for incorrect responses. In fact, the researchers found that when they set a high bar for confidence and let models think for even longer, the models’ accuracy actually decreased.
“This happens because answer accuracy is only part of a system’s performance,” Jurayj explains. “When you demand high confidence, letting the system think longer means it will provide more correct answers and more incorrect answers. In some settings, the extra correct answers are worth the risk. But in other, high-stakes environments, this might not be the case.”
Motivated by this finding, the team suggested three different “odds” settings to penalize wrong answers: 1) exam odds, where there’s no penalty for an incorrect answer; 2) “Jeopardy” odds, where correct answers are rewarded at the same rate incorrect ones are penalized; and 3) high-stakes odds, where an incorrect answer is penalized far more than a correct answer is rewarded.
They found that under stricter odds, a model should decline to answer a question if it isn’t confident enough in its answer after expending its compute budget. And at higher confidence thresholds, this will mean that more questions go unanswered—but that isn’t necessarily a bad thing.
“A student might be mildly annoyed to wait 10 minutes only to find out that she needs to solve a math problem herself because the AI model is unsure,” Jurayj says. “But in high-stakes environments, this is infinitely preferable to waiting five minutes for an answer that looks correct but is not.”
Now, the team is encouraging the greater AI research community to report their models’ question-answering performance under exam and Jeopardy odds so that everyone can benefit from AI with better-calibrated confidence.
“We hope the research community will accept our invitation to report performance in settings with non-zero costs for incorrect answers, as this will naturally motivate the development of better methods for uncertainty quantification,” says Jurayj.
Additional authors of this work include master’s student Jeffrey Cheng and Benjamin Van Durme, an associate professor of computer science affiliated with CLSP and the Human Language Technology Center of Excellence.