Emotion is the cornerstone of human interactions. In fact, the manner in which something is said can convey just as much information as the words being spoken. Emotional cues in speech are conveyed through vocal inflections known as prosody. Key attributes of prosody include the relative pitch, duration, and intensity of the speech signal. Together, these features encode stress, intonation, and rhythm, all of which impact emotion perception. While we have identified general patterns to relate prosody to emotion, machine classification and synthesis of emotional speech remain unreliable.
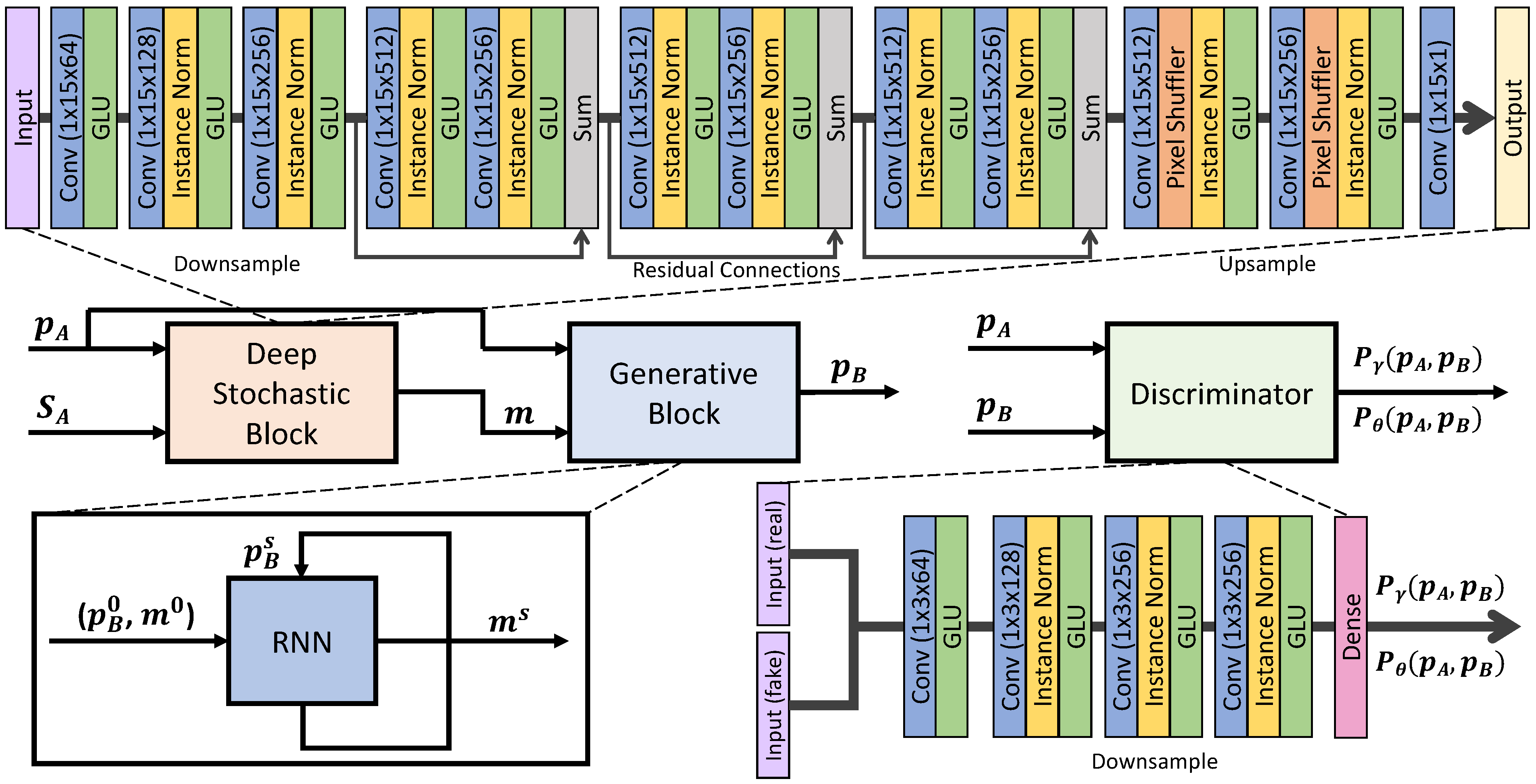 This project tackles the problem of multi-speaker emotion conversion, which refers to modifying the perceived affect of a speech utterance without changing its linguistic content or speaker identity. To start, we have curated the VESUS dataset, which represents one of the largest collections of parallel emotional speech utterances. From here, we have introduced a new paradigm for emotion conversion that blends deformable curve registration of the prosodic features with a novel variational cycle GAN architecture that aligns the distribution of prosodic embeddings across classes. We are now working on methods for open-loop duration modification that leverages a learned attention mechanism.
This project tackles the problem of multi-speaker emotion conversion, which refers to modifying the perceived affect of a speech utterance without changing its linguistic content or speaker identity. To start, we have curated the VESUS dataset, which represents one of the largest collections of parallel emotional speech utterances. From here, we have introduced a new paradigm for emotion conversion that blends deformable curve registration of the prosodic features with a novel variational cycle GAN architecture that aligns the distribution of prosodic embeddings across classes. We are now working on methods for open-loop duration modification that leverages a learned attention mechanism.
Beyond advancing speech technology, our framework has the unique potential to improve human-human interactions by modifying natural speech. Consider autism, which is characterized by a blunted ability to recognize and respond to emotional cues. Suppose we could artificially amplify spoken emotional cues to the point at which an individual with autism can accurately perceive them. Over time, it may be possible to retrain the brain of autistic patient to use the appropriate neural pathways.
Selected Publications
- R. Shankar, H.-W. Hsieh, N. Charon, A. Venkataraman. Multispeaker Emotion Conversion via a Chained Encoder-Decoder-Predictor Network and Latent Variable Regularization. In Proc. Interspeech: Conference of the International Speech Communication Association, 3391-3395, 2020.
- R. Shankar, J. Sager, A. Venkataraman. Non-parallel Emotion Conversion using a Pair Discrimination Deep-Generative Hybrid Model. In Proc. Interspeech: Conf of the International Speech Communication Association, 3396-3400, 2020.
- J. Sager, J. Reinhold, R. Shankar, A. Venkataraman. VESUS: A Crowd-Annotated Database to Study Emotion Production and Perception in Spoken English. In Proc. Interspeech: Conf of the International Speech Communication Association, 316-320, 2019. Selected for an Oral Presentation (<20% of Papers)
- R. Shankar, J. Sager, A. Venkataraman. A Multi-Speaker Emotion Morphing Model Using Highway Networks and Maximum Likelihood Objective. In Proc. Interspeech: Conference of the International Speech Communication Association, 2848-2852, 2019. Selected for an Oral Presentation (<20% of Papers)