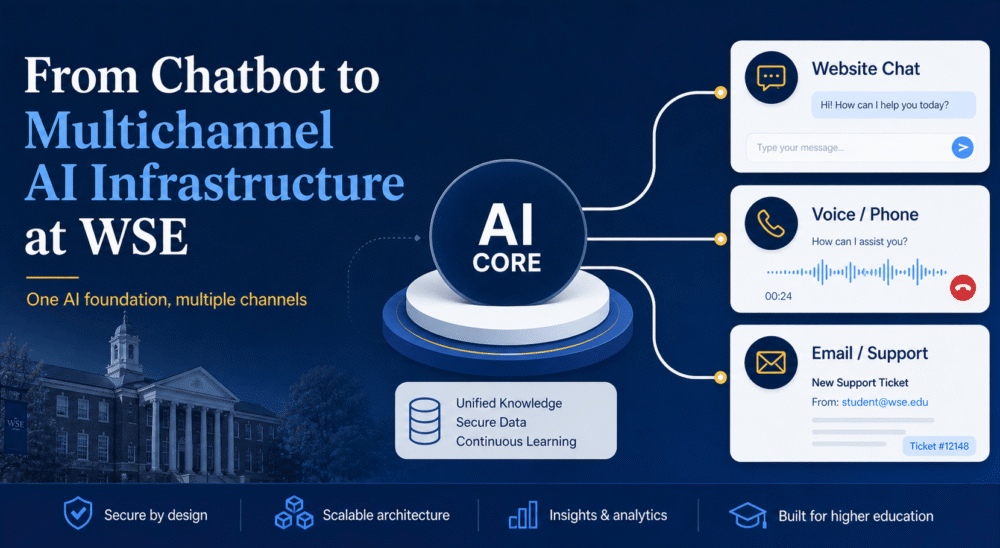
Launched in April, JayAI began as a website chat assistant for Johns Hopkins Engineering for Professionals. Since then, we’ve extended the same backend to an AI voice assistant on the main EP phone line, and an AI ticket assistant that drafts replies for staff review. This experience taught us a lesson about building a trusted AI foundation that can support multiple service channels without creating separate systems for each one.
Why this matters
Most users don’t think in terms of internal systems. They visit a website, send an email, call an office, or submit a ticket because they need an answer. Internally, those may be different workflows but, to the user, they are all part of the same service experience.
The important design choice was to avoid turning each channel into its own disconnected AI tool. Each channel has its own interface and safeguards, but each one connects back to the same governed backend: trusted knowledge, retrieval, routing logic, and tools.
For example, a prospective student might ask about the engineering management program through the website, call the office, or send an email that becomes a support ticket. Those should not be three separate support experiences with three separate sources of truth. They should be three entry points into the same trusted service layer.
Recognizing the need is the primary condition for design. –Charles Eames
The pattern
A practical multichannel AI system has three layers: user-facing channels, channel-specific workflows, and a shared knowledge foundation underneath. Each channel can have a different experience and different safeguards, while still drawing from the same trusted base.
Not every question should be handled the same way. Some answers should come from deterministic rules or structured data because they need to be exact and repeatable. Other questions benefit from retrieval and synthesis because the user needs explanation, comparison, or guidance. The shared backend makes that distinction once, then applies it consistently across channels.
Website chat
Visitors on ep.jhu.edu get answers grounded in EP content, with links back to the source.
Phone / voice
Callers get a spoken answer, a transfer to the right office, or a structured callback the team can act on.
Email / ticket
Each incoming email gets a draft response with supporting context, ready for staff to review, edit, and send.
The email/ticket workflow is intentionally review-first: JayAI prepares a draft and supporting context, but staff remain responsible for judgment, approval, escalation, and final response.
Business View: One AI Foundation, Multiple Channels
This is the simplest way to explain the strategy: three different user experiences, one trusted EP knowledge and decision layer underneath.
Plain-language takeaway: Build the trusted backend once, then expose it through chat, phone, and support workflows with channel-specific safeguards.
Infrastructure View: Shared Backend With Channel-Specific Interfaces
This version is more technical but still high level: each channel has its own interface and orchestration layer, but they all reuse the same JayAI data, retrieval, answer rules, and model access path.
Technical takeaway: the channel code stays separate, but the knowledge layer is shared. That keeps answers consistent while allowing each channel to have its own UX, safety rules, routing behavior, and human review model. The latency budget of each channel turned out to be the most consequential design constraint. Voice was hardest by far since a caller expects an answer in seconds, which leaves no room to query many sources, run heavier reasoning models, or revise a draft before speaking. Chat sits in the middle. It has to feel responsive, but there’s space for retrieval and lighter reasoning. Email and ticketing are the most forgiving where you have minutes or hours of working time, and the system can use reasoning models, chain more tools, pull from more data, and produce a draft before staff review.
The bigger takeaway is that user expectations of speed shape both answer quality and the architecture underneath. The faster the channel, the harder to integrate depth, sourcing, and reasoning, and the more those constraints ripple through every layer of the system.
What this means for labor
The goal is to reduce repetitive intake, help users get to the right answer faster, and give staff better starting points for review, escalation, and advising.
When the shared knowledge layer improves, every channel can benefit. That creates a better service loop where user questions reveal gaps, quality checks identify weak spots, and staff feedback improves the underlying system over time. But by building in careful engineering harnessing, you can monitor the user logs in addition to staff feedback every 24 hours and have the system iterate, test, and push enhancements.
What other teams can reuse
The reusable lesson is the pattern, not the interface. Start with real user questions, identify trusted information sources, separate exact-answer workflows from interpretive guidance workflows, and keep human review in the loop where judgment matters.
- Start with the questions people actually ask.
- Identify the trusted sources of truth.
- Separate exact-answer workflows from interpretive guidance workflows.
- Keep human review in the loop where judgment matters.
- Assign clear ownership for content, rules, escalation paths, and quality review.
- Measure usage, gaps, handoffs, and draft quality from day one.
 Stay Connected
Stay Connected
Recent Comments