Introduction
In recent years, smartphones like Apple’s Siri and home speakers like Amazon’s Alexa and Google home have made speech a common way to communicate with machines around the world. This rapid development in human-machine interaction favors the development of speech interfaces as a natural and easy way to communicate with machines and mobile devices. Our research is focused on extracting useful and varied kinds of information from human voices. The speech signal is complex and contains a tremendous amount of diverse information including, but not limited to: classical linguistic message (the most important information, humans use for everyday communication), language spoken, speaker characteristics (i.e., identity, age, and gender), speaker’s emotional state and possible degree of intoxication. The last two characteristics, emotional state, and degree of intoxication can enable applications across a broad spectrum ranging from health-related applications. For example, a patient’s emotional state can be identified by using a dialogue system, which would be capable of producing reports for a physician based on several communications between the patient and the system.
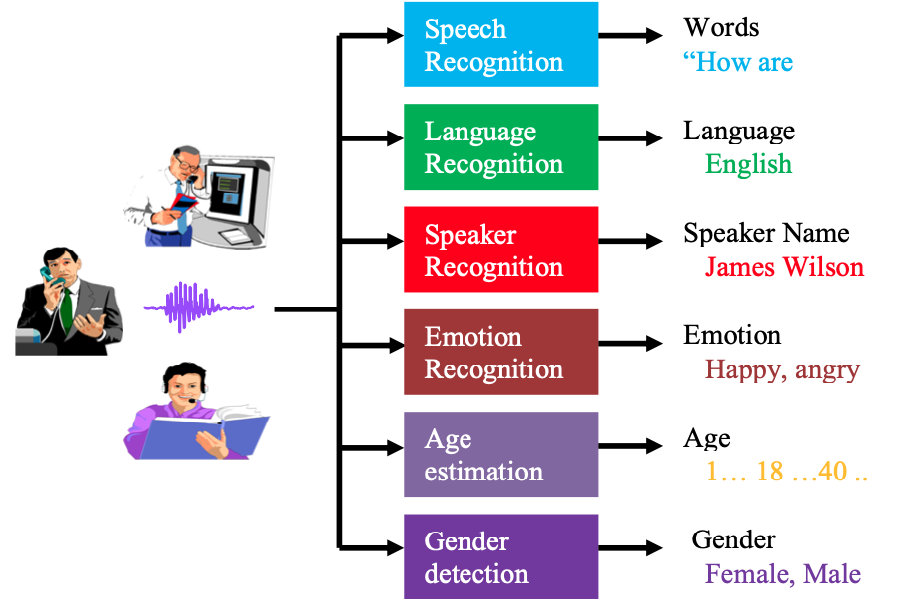
Speaker characterization
One of our core research areas is automatic speaker recognition [1,2,3]. This problem is usually divided into two main application areas. The first one is speaker identification, which consists of selecting, among several possible identities, the speaker who produces a specific speech segment. The second one is speaker verification, in which the system determines whether the identity of the speaker who produces the speech test segment is the same as a claimed (previously enrolled) target speaker. The speaker recognition problem has recently attracted considerable interest due to the rapid growth of mainstream voice servers in areas, such as banking, which must provide secure access to customer information. Speaker recognition systems can also be used to unlock a personal smartphone without being obliged to enter a passcode every time. These systems are also being used in forensics and law enforcement. There have been a few court cases where speech samples played a critical role in the trial case, such as the high profile case involving the death of Trayvon Martin. However, much work remains to be done before speaker recognition systems can be trusted in court. In addition, only verify the identity of the speaker, recently we have been exploring the extraction of extra information about the speaker, including age [20,21,22], gender, height, and weight, that can help to create more evidence about a crime suspect. However, these speaker characteristics can also be helpful for commercial applications. A related application that we explored within the speaker recognition spectrum is speaker diarization [5,6] which consists of determining and merging segments of the same speaker(s) that occur across an unlabeled speech recording. Diarization systems are needed for indexing multimedia content.
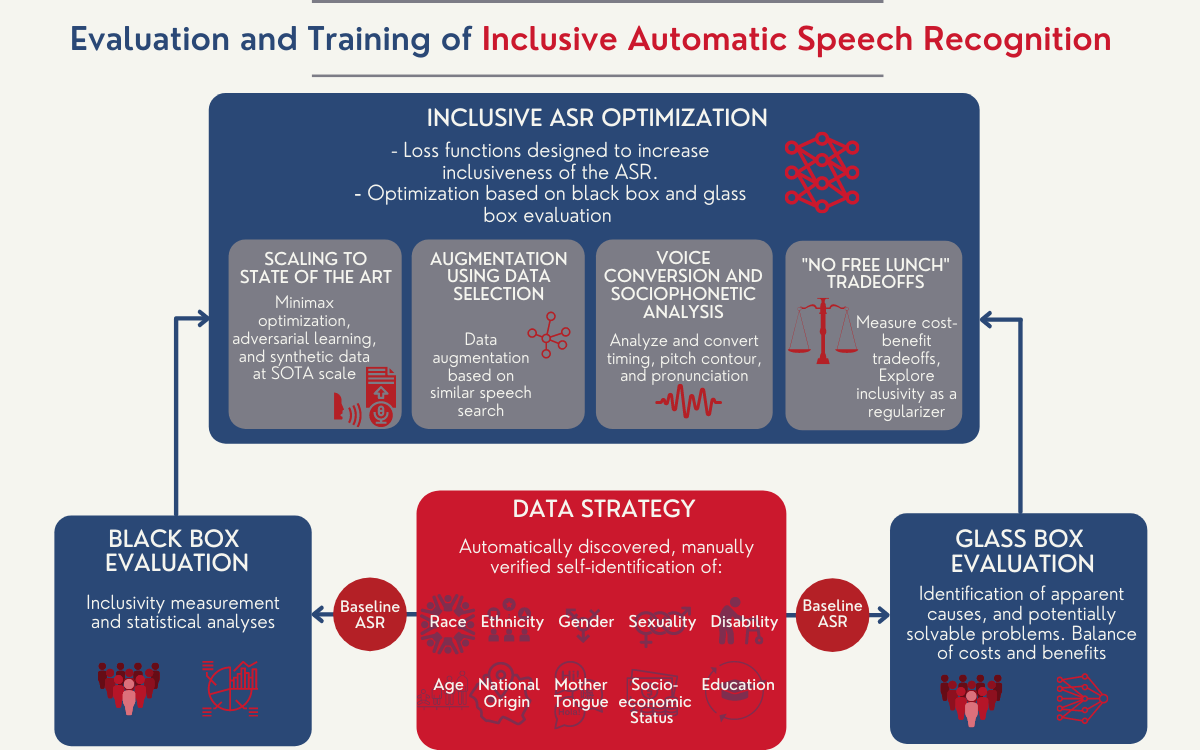
Inclusive Automatic Speech Recognition
Automatic speech recognition (ASR) has the potential to democratize the flow of information: artificially intelligent dialog agents can provide information to people who would otherwise not know where to look. The ASR community's relentless focus on minimum word error rate (WER) over the past fifty years has resulted in a productivity tool that works extremely well for those of us whose speech patterns match its training data: typically, we are college-educated first-language speakers of a standardized dialect, with little or no speech disability. For many groups of people, however, ASR works less well, possibly because their speech patterns differ significantly from the standard dialect (e.g., because of regional accent), because of intra-group heterogeneity (e.g., regional African American languages), or because the speech pattern of each individual in the group exhibits variability (e.g., people with severe disabilities, or second-language learners).
Our is to create a new paradigm for the evaluation and training of inclusive automatic speech recognizers. We are currently working with scientists from University of Illinois and Technical Delft University to deliver more iclusive ASRs.
Emotion Recognition
In the last few years, there has been a significant increase in interest in the field of emotion recognition based on different human modalities, such as speech, heart rate, etc. Building a robust emotion detection system can be useful in several areas, such as medical and telecommunications. In the medical field, detecting emotions can be an essential tool for detecting and monitoring patients with mood and depression disorder. Physicians increasingly face the severe problem of not being able to see patients daily to evaluate and monitor their progress. To help the physician to be continuously informed about the emotion status of their patients, we propose to design an automatic dialogue system capable of capturing and analyzing the emotion of patients from their voice. There are three different modalities we can consider for capturing speech pattern data from the patients with a mood disorder, each with its own balance of advantages and disadvantages. First, we can use a vocal server that calls the patients and delivers brief automated interactive voice questionnaires. The calls can be made to the patients’ mobile phones, or through new-generation devices such as Amazon Echo or Google Home. Second, we can design an embedded system directly in a mobile smartphone that can passively record patients’ real-world phone conversations in naturalistic settings. Third, in a more futuristic approach, we could use interactive social robots to capture speech data in a structured and interactive fashion that is more evocative of real-world human communication.
In more recent work [24], we started exploring the use of emotion and sentiment recognition to measure and predict customer satisfaction from conversational telephone calls in call centers. This work can be instrumental for financial advisors to design better marketing strategies. Typically, customer satisfaction is determined using a post-call survey presented to the customer, which is of limited value, given that only a subset of customers completes this survey. We propose several methods for automatically predicting the overall customer satisfaction in the calls in a call center.
Language Recognition
Another information extraction application for speech that we have contributed to is language recognition. As with speaker recognition technology, there are two typical uses for language identification [11,14,15,16]. The first task is automatically identifying the language spoken in a speech sample. The second task is language verification, which consists of verifying if a specific language was the one spoken in a given recording. In addition to our work on language recognition, I have also worked on dialect recognition, which consists of identifying the speaker’s dialect [12,13].
Dialog Act Systems
Dialog acts can be interpreted as the atomic units of a conversation, more fine-grained than utterances, characterized by a specific communicative function. The ability to structure a conversational transcript as a sequence of dialog acts—dialog act recognition, including the segmentation—is critical for understanding dialog. In our Lab, we also work on spoken language understanding applications.
Automatic Speech Recognition in Low-resourced Languages
Automatic Speech Recognition (ASR) is one of the technologies deployed on a massive scale with the highest impact of the 21st century. It has achieved enormous advancement during the past fifteen years, enabling automatic transcription, translation, and the ubiquitous appearance of digital assistants, among other applications. Combined with spoken language understanding, ASR has the potential to automate numerous processes that require spoken communication, such as requests for support and knowledge. Typically, the development of ASR systems requires hundreds to thousands of hours of speech recordings and their correspondent transcriptions. Unfortunately, only a small number of the world's languages is sufficiently resourced to build speech processing systems, while the amount of transcribed speech data for most of the 7,000 spoken languages in the world is very limited or nonexistent. This results in digital divides that can only be fixed with large investments in speech resources, if considering only traditional ways to develop ASR models for new languages. In our Lab, we work to develop new techniques to provide more precise ASR in low-resourced languages.
Speech representation and robustness
We am chiefly interested in applying machine-learning approaches to speech modeling. Our goal is to develop a single and common speech representation that can model all the speech characteristics, and that can be shared by several speech applications. This method will be developed as a form of a toolkit that will take a speech segment as input and generate a single vector that could be used to characterize the speaker identity, gender, age, emotion, the topic, the type of spoken language, the type of the transmission channel and all other speech information. The extraction of any information from the speech will become as easy as manipulating the obtained vectors.
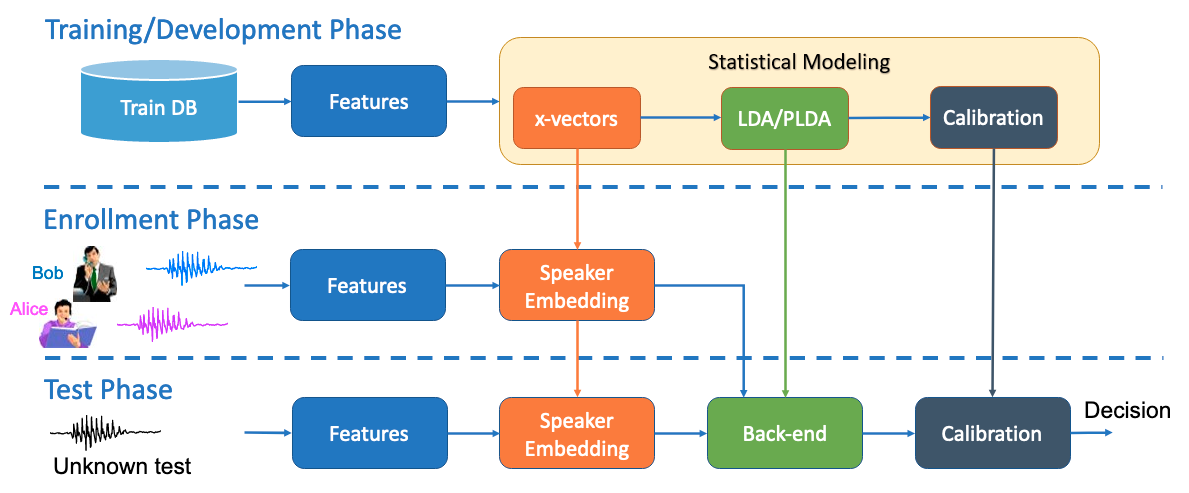
Dr. Dehak's main contribution in this area is the development of the I-vector representation for speaker and language recognition [2,3,11], which is one step toward the realization of our research goal. Dr. Dehak first introduced this method, which has become the state-of-the-art in this field, during the 2008 summer CLSP workshop at Johns Hopkins University. This method is a statistical, data-driven approach for feature extraction, which provides an elegant framework for audio classification and identification in general. It consists of mapping audio segments with varying lengths to a single low dimensional space which simplifies the comparison and classification tasks. This mapping is based on factor analysis model, which is a linear statistical method applied to model all different variabilities between several recordings on the Gaussian mixture model space. This approach has had an enormous impact across several speech technologies such as speaker clustering and diarization, face recognition, emotion, language, and dialect identification. It has also been used for speaker adaptation in deep neural network-based speech recognition system, as well as natural language processing. In recognition of its popularity in the speech community, Dr. Dehak was awarded the 2012 Young Author Best Paper Award from the IEEE Signal Processing Society. The award was attributed to my journal paper introducing the I-vector to the speech and language community.
As described previously, the speech signal contains a lot of complex information. However, most of the methods, such as the classical I-vector, used to represent different recordings in a common space are based on a linear approach. We believe that non-linear methods will be more suitable to model all the information present in the speech signal and more appropriate to learn the speech manifold. Recently, an end-to-end speaker embedding has achieved impressive results, especially when trained on a large number of speakers. There have also been many advances in the field of non-linear speech processing and a deep neural network that show a signal of success of using non-linear methods to model speech signals. Our research group is currently extending the I-vector representation to non-linear models [23]. We are also working on building an end-2- end system [9,14,20] without going through a speech representation based on deep neural network for speaker, language, and emotion recognition and age estimation [9,14,20,22].
References
1. N. Dehak, P. Dumouchel, P. Kenny “Modeling Prosodic Features with Joint Factor Analysis for Speaker Verification,” IEEE Trans. Audio, Speech, and Language Proc., 15(7), 2095–2103, 2007.
2. N. Dehak, P. Kenny, R. Dehak, P. Dumouchel, and P. Ouellet,“Front-End Factor Analysis for Speaker Verification,” IEEE Trans. Audio, Speech, and Language Proc., 19(4), 788–798, 2011. [Young Author Best Paper Award]
3. N. Dehak, R. Dehak, P. Kenny, N. Brummer, P. Ouellet and P. Dumouchel. “Support Vector Machines versus Fast Scoring in the Low-Dimensional Total Variability Space for Speaker Verification,” Proc. Interspeech, Brighton, UK, pp. 1559–1562, September 2009.
4. N. Dehak, Z. Karam, D. Reynolds, R. Dehak, W. Campbell, and J. Glass, “A Channel- Blind System for Speaker Verification,” Proc. ICASSP, pp. 4536–4539, Prague, 2011.
5. S. Shum, N. Dehak, E. Chuangsuwanich, D. Reynolds, and J. Glass, “Exploiting Intra-Conversation Variability for Speaker Diarization,” Proc. Interspeech, pp. 945–948, Florence, 2011.
6. S. Shum, N. Dehak, and J. Glass, “Unsupervised Methods for Speaker Diarization: An Integrated and Iterative Approach,” IEEE Trans. Audio, Speech, and Language Proc., 21(10), 2015–2028, 2013.
7. P. Dumouchel, N. Dehak,Y. Attabi, R. Dehak and N. Boufaden.“Cepstral and Long-Term Featuresf or Emotion recognition,” Proc. Interspeech, Brighton, UK, pp. 344–347, September 2009. [The Open Performance Sub-Challenge Prize]
8. E. Hill, D. Han, P. Dumouchel, N. Dehak, T. Quatieri, C. Moehs, M. Oscar-Berman, J. Giordano, T. Simpatico, and K. Blum, “Long Term SuboxoneTM Emotional Reactivity As Measured by Automatic Detection in Speech,” PLoS ONE, 8(7),1–14, 2013.
9. J. Cho, R. Pappagari, P. Kulkarni, J. Villalba, Y. Carmiel, and N. Dehak, “Deep Neural Networks for Emotion Recognition Combining Audio and Transcripts,” Proc. Interspeech 2018, pp. 247–251, Hyderabad, India, September 2018.
10. M. Sarma, P. Ghahremani, D. Povey, N. K. Goel, K. K. Sarma, and N. Dehak, “EmotionIdentification from Raw Speech Signals Using DNNs,” Proc. Interspeech 2018, pp. 3097–3101, Hyderabad, India, September 2018.
11. N. Dehak, P. Torres-Carrasquillo, D. Reynolds, and R. Dehak, “Language Recognition via Ivectors and Dimensionality Reduction,” Proc. Interspeech, pp. 857–860, Florence, Italy, August 2011
12. H. Bahari, N. Dehak, H. Van hamme, L. Burget, A. Ali, and J. Glass, “Non-Negative Factor Analysis for Gaussian Mixture Model Weight Adaptation for Language and Dialect Recognition,” IEEE Trans. Audio, Speech, and Language Proc., 22(7), 1117– 1129, 2014.
13. A. Ali, N. Dehak, P. Cardinal, S. Khuruna, S. Yella, J. Glass, P. Bell, and S. Renals, “Automatic Dialect Detection in Arabic Broadcast Speech,” Proc. Interspeech, pp. 2934– 2938, San Francisco, USA, September 2016.
14. J. Villalba, N. Brummer, and N. Dehak, “End-to-End versus Embedding Neural Networks for Language Recognition in Mismatched Conditions,” Odyssey speaker and language recognition workshop, pp. 112–119, Les Sables d’Olonne, France, June 2018.
15. S. Shum, D. F. Harwath, N. Dehak, and J. R. Glass, “On the Use of Acoustic Unit Discovery for Language Recognition,” IEEE/ACM Trans. Audio, Speech, and Language Proc., 24(9), 1665–1676, 2016.
16. F. Richardson, D. Reynolds, and N. Dehak, “Deep Neural Network Approaches to Speaker and Language Recognition,” IEEE Signal Processing Letters Proc., 22(10), 1671–1675, 2015.
17. J. R. Orozco-Arroyave, J.C. Vásquez-Correa, J. F. Vargas-Bonilla, R. Arora, N. Dehak, P.S. Nidadavolu, H. Christensen, F. Rudzicz, M. Yancheva, H. Chinaei, A. Vann, N. Vogler, T. Bocklet, M. Cernak, J. Hannink, and E. Nöth, “NeuroSpeech: An Open- Source Software for Parkinson’s Speech Analysis,” Digital Signal Processing, Volume 77, Pages 207-221, June 2018.
18. L. Moro-Velazquez, J.A. Gómez-García, J.I. Godino-Llorente, J. Villalba, J.R. Orozco- Arroyave,and N. Dehak, “Analysis of Speaker Recognition Methodologies and the Influence of Kinetic Changes to Automatically Detect Parkinson’s Disease,” Applied Soft Computing, 62, Pages 649-666. 2018.
19. L. Moro-Velazquez, J.A. Gómez-García, J.I. Godino-Llorente, J. Rusz, S. Skodda, F. Grandas-Pérez, J. M. Velázquez, E. Nöth, J. R. Orozco-Arroyave, and N. Dehak, “Study of the Automatic Detection of Parkison’s Disease Based on Speaker Recognition Technologies and Allophonic Distillation,” Proc. 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, pp. 1404–1407. Honolulu, Oahu, July 2018.
20. R. Zazo, P.S. Nidadavolu, N. Chen, J. Gonzalez-Rodriguez, and N. Dehak,“Age Estimationin Short Speech Utterances Based on LSTM Recurrent Neural Networks,” IEEE Access 2018, Pages 22524-22530, March 2018.
21. N. Chen, J. Villalba, Y. Carmiel, and N. Dehak, “Measuring Uncertainty in Deep Regression Models: The case of Age Estimation from Speech,” Proc. ICASSP, pp. 4939– 4943, Calgary, Canada, April 2018.
22. P. Ghahremani, P. S. Nidadavolu, N. Chen, J. Villalba, D. Povey, S. Khudanpur, and N. Dehak, “End- to-End Deep Neural Network Age Estimation,” Proc. Interspeech, pp. 277– 281, Hyderabad, India, September 2018.
23. N. Chen, J. Villalba, and N. Dehak, “An Investigation of Non-linear i-vectors for Speaker Verification,” Proc. Interspeech, pp. 87–91, Hyderabad, India, September 2018.
24. R. Pappagari,J. Villalba, P. Zelasko, Y. Carmiel, and N. Dehak, “Analysis of Customer Satisfaction Prediction from Conversational Speech Transcripts,” Submitted to IEEE/ACM Trans. Audio, Speech, and Language Proc., 2019.
