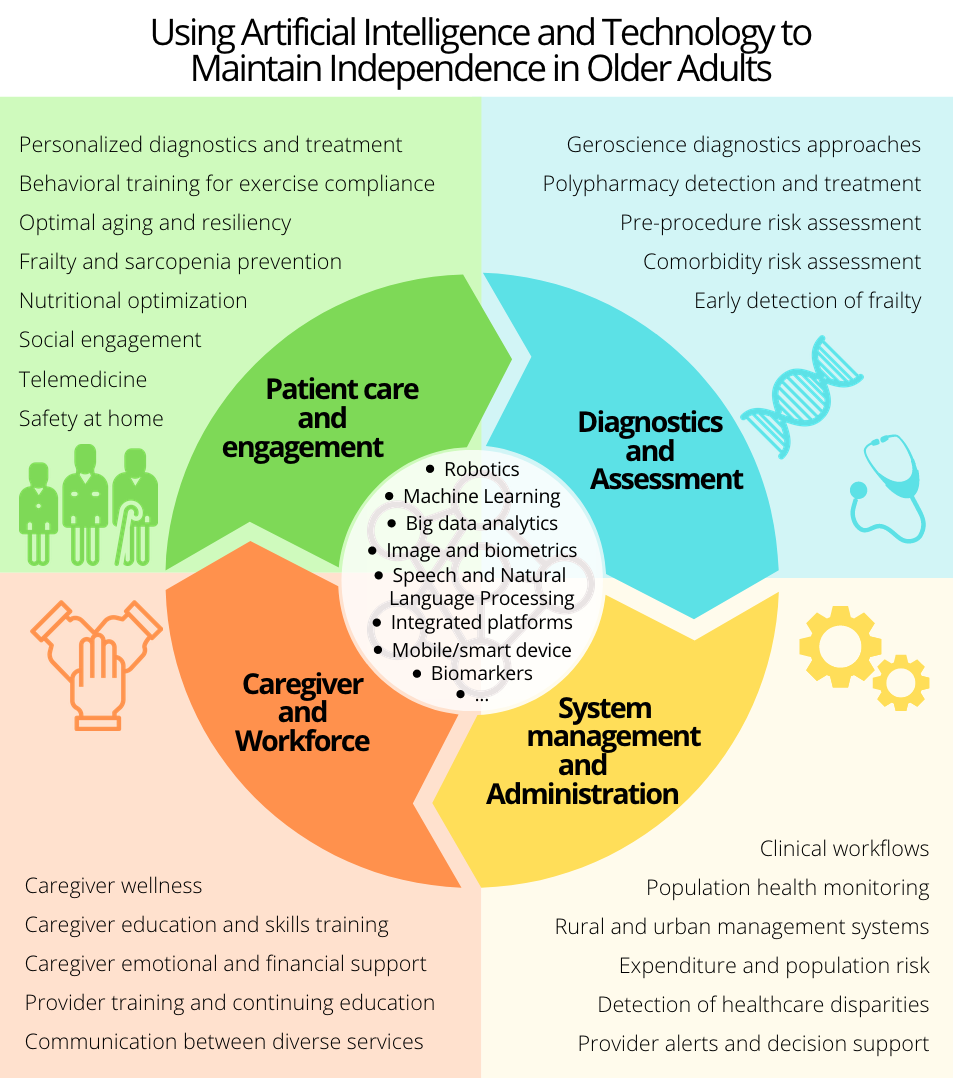
Introduction
Our commitment is to use artificial intelligence and machine learning techniques to find biomarkers to reduce diagnosis time of neurological diseases, predict the frailty of subjects, and optimize the decisions to be taken with patients in critical care. During the last decade, there has been an increase of interest in the use of artificial intelligence in medicine, especially since the arrival of new paradigms employing deep neural networks that can boost the diagnosis and assessment accuracy in multiple scenarios. With these motivations and to fulfill our commitment, we are combining our experience in biomedical engineering, human language technologies, signal processing, and machine learning acquired in previous projects to collaborate with a multidisciplinary group at the Johns Hopkins Hospital in the proposal of new diagnostic and prognostic tools that will provide faster and more accurate diagnosis.
Our main goals are to: provide non-invasive, cost-effective and accurate tools for monitoring and diagnosis of individuals with neurodegenerative diseases; measure and predict frailty; and to monitor the onset of dementia and post-surgical delirium in older adults. These tools will provide a more personalized treatment that will improve the prognosis of the individuals and increase their independence.
Research on neurodegenerative diseases
The current required period of clinical diagnosis for Parkinson Disease (PD) ranges from months to years. Emerging therapies to slow down or even stop the advancement of PD underscore the importance developing effective early detection procedures. This need has motivated me to work in the proposal and analysis of several schemes employing speech [1], eye-movement (saccades and fixations) [2], and limb movement [12] signals to detect and assess PD automatically and to differentiate it from mimicking syndromes. Some of the approaches that we have proposed use speech and speaker recognition technologies adapted to the particularities of the parkinsonian speech, obtaining accuracies up to 94% in the discrimination between speakers with and without PD [3]. This type of analysis during diagnosis, being non-invasive and cost-effective, has demonstrated to provide relevant and objective information about the presence of PD from early to advanced stages [4]. The main difference between the schemes that we have proposed and others found in the literature is that our last works validate the results in several speech corpora simultaneously, preforming cross-corpora analyses to analyze corpus dependence [3, 5]. Moreover, we have analyzed the influence of PD on different class manners and phonemes, which will allow us to design better speech tests for patients in the future [3, 5]. In the same sense, our students have used natural language processing technologies, combined with automatic acoustic analysis of speech to assess the cognitive state of patients with Alzheimer’s Disease (AD). They employed transformer-based neural networks and deep neural networks embeddings for the detection and assessment of AD [6]. Additionally, we have collaborated with Université du Québec, and professor Patrick Cardinal, to obtain severity biomarkers in PD patients employing accelerometers and machine learning [12].
Frailty and post-operative delirium prognosis
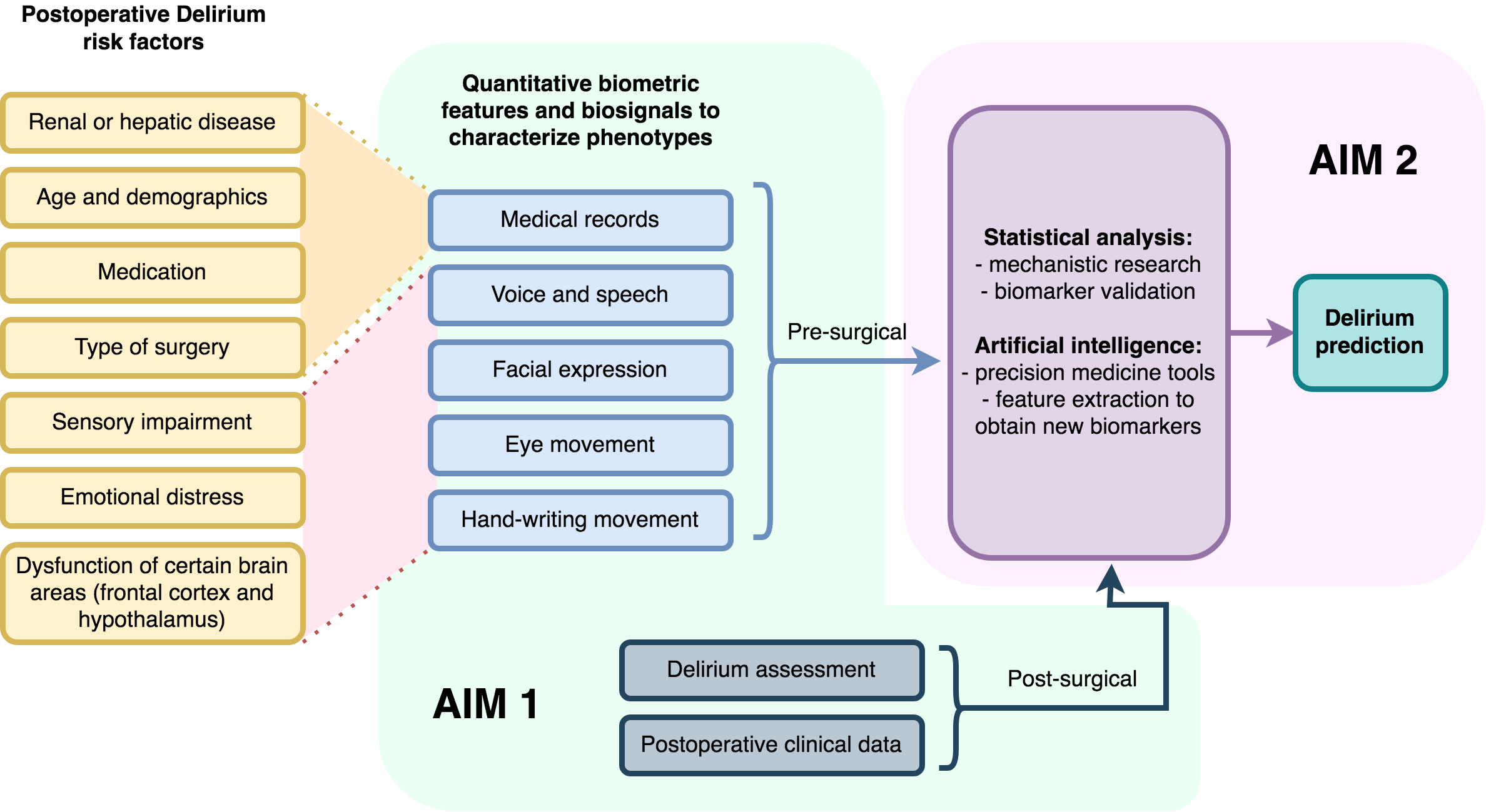
The pathophysiology of delirium may be viewed as a complex interplay between susceptibility factors and precipitating mechanisms. Susceptibility factors include older age, comorbid disease, psychiatric and cognitive syndromes, while precipitating mechanisms include infection, selected types of surgery, and admission to the intensive care unit. Biological mechanisms linked to delirium include inflammation, synaptic dysfunction, neuroendocrine changes, and cortical atrophy particularly in the prefrontal regions mediating executive function and personality expression. Factors contributing to delirium have been combined in multivariable clinical prediction models that estimate delirium risk and outcomes. However, these models are limited in accuracy and fail to capture fundamental phenotypic characteristics.
Frailty has been defined as a clinical syndrome involving self-reported exhaustion, weakness, slowness, and low physical activity. The physical frailty phenotype has more recently approached “a state of health resulting from dysregulation in physiological mechanisms”. Frail individuals are at increased risk of adverse outcomes such as falls, hospitalization, cognitive decline, and death. The literature proposes certain methods to measure or assess frailty, like the Johns Hopkins Frailty Risk Assessment Calculator. However, almost no study proposes frailty scores for older adults undergoing major surgery.
We hypothesize that a quantitative and detailed analysis of movement and cognitive aspects can provide frailty scores in older adults and predict postoperative outcomes in those that are undergoing major surgery, such as delirium. We consider that these scores would be especially relevant for patients that require surgery, given that these are at a higher risk of adverse contingencies triggered by the operation.
Previous research, has shown that quantitative signals in phenotypic elements such as voice and speech or eye movements, are biomarkers of latent, incipient or overt neurological syndromes such as movement disorders or dementia [1-6, 12]. Currently, we work with an interdisciplinary team, including Dr. Robert D. Stevens, extracting information from signals in recorded speech, eye movements and handwriting, and selected clinical data to train statistical and artificial intelligence classifiers with the goal of building robust clinically relevant models to quantify frailty and delirium risk.
Dysarthria
Automatic speech recognition (ASR) has the potential to greatly improve the lives of people with motor disorders, e.g., by providing them with voice dialing, voice access to the internet, and, with appropriate safety precautions, voice-commanded robotics. Nevertheless, the potential benefits of speech technology remain unmet because many motor disorders result in dysarthria, which often manifests itself as slurred or slow speech. Where moderate dysarthria prevents a person from communicating with humans, even mild dysarthria prevents a person from communicating with ASR. Both the ASR and human listeners can be trained to understand dysarthric speech, but for both humans and machines, the training is slow: a human listener may require several hours of exposure to a person with dysarthria before learning their speech patterns, while an ASR may require several dozen hours of speech data to learn a good speaker-dependent model. Dysarthria is a frequent symptom of many types of neuromotor disorders, with prevalence estimates of 10-60% among people with traumatic brain injury (TBI), 31-88% among people with Cerebral Palsy (CP), 72-100% uniformly across five types of Parkinsonian Disorders (PD), and 75-100% among people with Amyotrophic Lateral Sclerosis (ALS).
We are currently working on voice conversion and adaptation of ASR to provide new tools for people with dysarthria. The convergence of these technologies now makes it possible to have a significant impact on the quality of life of people with dysarthria. We aim to improve the training strategies for both human listeners and ASR systems for improved recognition of dysarthric speech. Specifically, we propose three innovative specific aims that will lead to technologies and methodologies improving the lives of patients with dysarthria.
Voice Pathology
In clinical practice, specialists usually assess the voice and speech of patients to support the diagnosis of voice pathologies by employing perceptual protocols. However, these subjective methods involve a high intra- and inter-rater variability, making the use of objective biomarkers or systems necessary to perform a more reliable assessment of the patient’s voice to detect and monitor a pathology. New signal processing technologies have provided some biomarkers such as jitter, shimmer, or glottal-to-noise ratio to measure perturbations in the voice signal. Despite their popularity, our analyses indicate that some of these features are not reliable enough to be used for clinical assessment [8]. Therefore, we have proposed a new group of biomarkers called modulation spectrum morphological parameters that have demonstrated to have high relevance in the detection and evaluation of vocal pathologies. These parameters have been used in automatic detection systems and objective GRBAS assessments, obtaining high performance in the quality of voice applications [9]. This has been demonstrated in the 2018 FEMH Challenge, where the proposed scheme using some modulation spectrum morphological parameters was selected as one of the five best approaches [10]. Finally, in collaboration with Universidad Politecnica de Madrid (Prof. Juan Ignacio Godino-Llorente) we analyzed for the first time the effects of supraglottal track surgery in speech recognition systems. The related study suggested that certain surgeries as tonsillectomy, produce changes in the voice of patients in the long term that can lead to failures in their identification through speech [11].
Our plan is to employ signal processing and machine learning to characterize voice pathologies and support the objective diagnosis and assessment of organic and neurological diseases. To carry out this type of research, we have started a collaboration with the Otolaryngology-Head and Neck Surgery Department at the Johns Hopkins Hospital.
References
[1] Moro-Velazquez, L., Gómez-García, J. A., Godino-Llorente, J. I., Villalba, J., Orozco-Arroyave, J. R., & Dehak, N. (2018). Analysis of speaker recognition methodologies and the influence of kinetic changes to automatically detect Parkinson’s Disease. Applied Soft Computing, 62, 649-666.
[2] Gómez-García, J. A., Moro-Velázquez, L, and Godino-Llorente, J. I. "Analysis of video-oculographic registers for the discrimination of Parkinson’s disease." School and symposium on advanced neurorehabilitation (SSNR2018).
[3] Moro-Velazquez, L., Gomez-Garcia, J. A., Godino-Llorente, J. I., Grandas-Perez, F., Shattuck-Hufnagel, S. Yague-Jimenez, V., and Dehak, N. (2019). Phonetic relevance and phonemic grouping of speech in the automatic detection of Parkinson’s disease. Scientific reports 9, 19066.
[4] Moro-Velazquez, L., Gomez-Garcia, J. A., Arias-Londoño, J. D., Dehak, N., & Godino-Llorente, J. I. (2021). Advances in Parkinson’s Disease detection and assessment using voice and speech: A review of the articulatory and phonatory aspects. Biomedical Signal Processing and Control, 66, 102418.
[5] Moro-Velazquez, L., Gomez-Garcia, J. A., Godino-Llorente, J. I., Villalba, J., Rusz, J., Shattuck-Hufnagel, S. and Dehak, N. (2019). A forced Gaussians based methodology for the differential evaluation of Parkinson’s Disease by means of speech processing. Biomedical Signal Processing and Control, 48, 205-220.
[6] Pappagari, R., Cho, J. J., Moro-Velazquez, L. and Dehak, N. (2020). Using state of the art speaker recognition and natural language processing technologies to detect Alzheimer’s disease and assess its severity. Proc. Interspeech 2020.
[7] Moro-Velazquez, L., Cho, J. J., Watanabe, S., Hasegawa-Johnson, M. A., Scharenborg, O., Kim, H. and Dehak, N. (2019). Study of the performance of automatic speech recognition systems in speakers with Parkinson’s Disease. Proc. Interspeech 2019, 3875-3879.
[8] Gómez-García, J. A., Moro-Velázquez, L., Arias-Londoño, J. D., & Godino-Llorente, J. I. (2021). On the design of automatic voice condition analysis systems. Part III: review of acoustic modelling strategies. Biomedical Signal Processing and Control, 66, 102049.
[9] Moro-Velazquez, L., Gómez-García, J. A., Godino-Llorente, J. I., Andrade-Miranda, G. (2015). Modulation spectra morphological parameters: a new method to assess voice pathologies according to the GRBAS scale. BioMed research international, 2015.
[10] Arias-Londoño, J. D., Gómez-García, J. A., Moro-Velazquez, L. and Godino-Llorente, J. I. (2018). ByoVoz Automatic Voice Condition Analysis System for the 2018 FEMH Challenge. Proceedings of the 2018 IEEE International Conference on BigData.
[11] Moro-Velazquez, L., Hernandez-Gonzalez, E., Gomez-Garcia, J. A., Godino-Llorente, J. I., and Dehak, N. (2020). Analysis of the effects of supraglottal tract surgical procedures in automatic speaker recognition performance. IEEE/ACM Transactions on Audio, Speech and Language Processing, 28, 798-812.
[12] Gill, M. P., Chen, N., Bhati, S. Joshi, S., Moro-Velazquez, L. Predicting Parkinson's medication status, and severity of tremor and dyskinesia from wearable devices using tsfresh, xgboost and SVRs. https://www.synapse.org/#!Synapse:syn21781149/wiki/602894.
