In this page we include code and data from some of the studies authored our students and faculty. Some of them are the result of collaborations with other labs and institutions.
Lhotse: a speech data representation library for the modern deep learning ecosystem
Code can be found here.
Lhotse is a Python library aiming to make speech and audio data preparation flexible and accessible to a wider community. Alongside k2, it is a part of the next generation Kaldi speech processing library.
Main goals:
- Attract a wider community to speech processing tasks with a Python-centric design.
- Accommodate experienced Kaldi users with an expressive command-line interface.
- Provide standard data preparation recipes for commonly used corpora.
- Provide PyTorch Dataset classes for speech and audio related tasks.
- Flexible data preparation for model training with the notion of audio cuts.
- Efficiency, especially in terms of I/O bandwidth and storage capacity.

Working for a better future
Multilingual Automatic Speech Recognition: Hybrid and End-to-end models
Code can be found here.
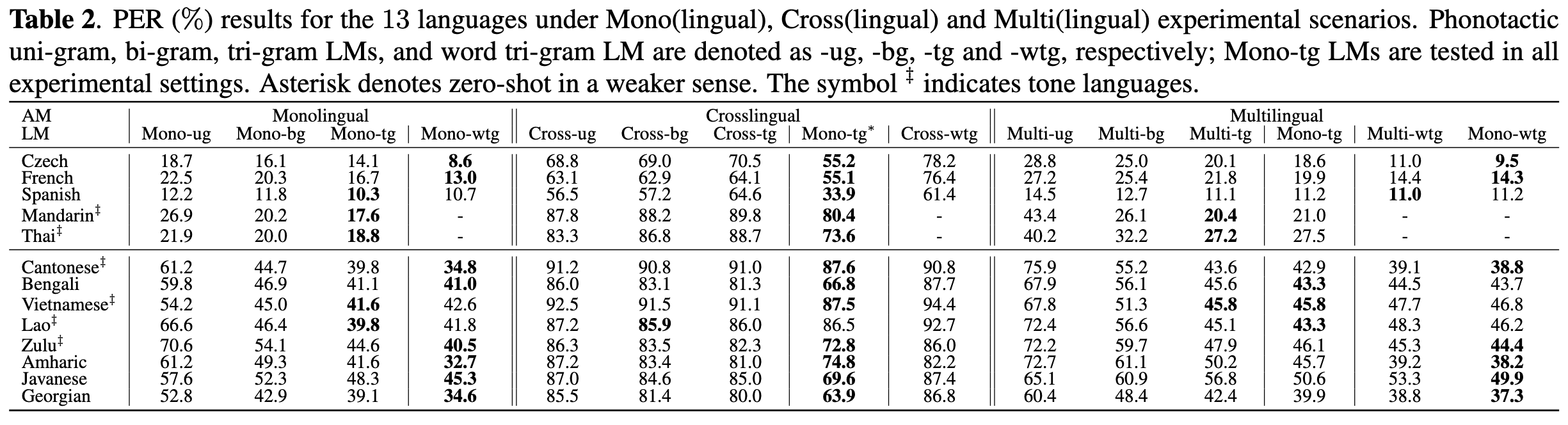
This will create multiple monolingual, multi-lingual and cross-lingual hybrid and end-to-end automatic speech recognition systems in different languages and about 20 experiments from the paper "How Phonotactics Affect Multilingual and Zero-Shot ASR Performance."
Working for a better future
Multilingual Automatic Speech Recognition: End-to-end models
Code can be found here.
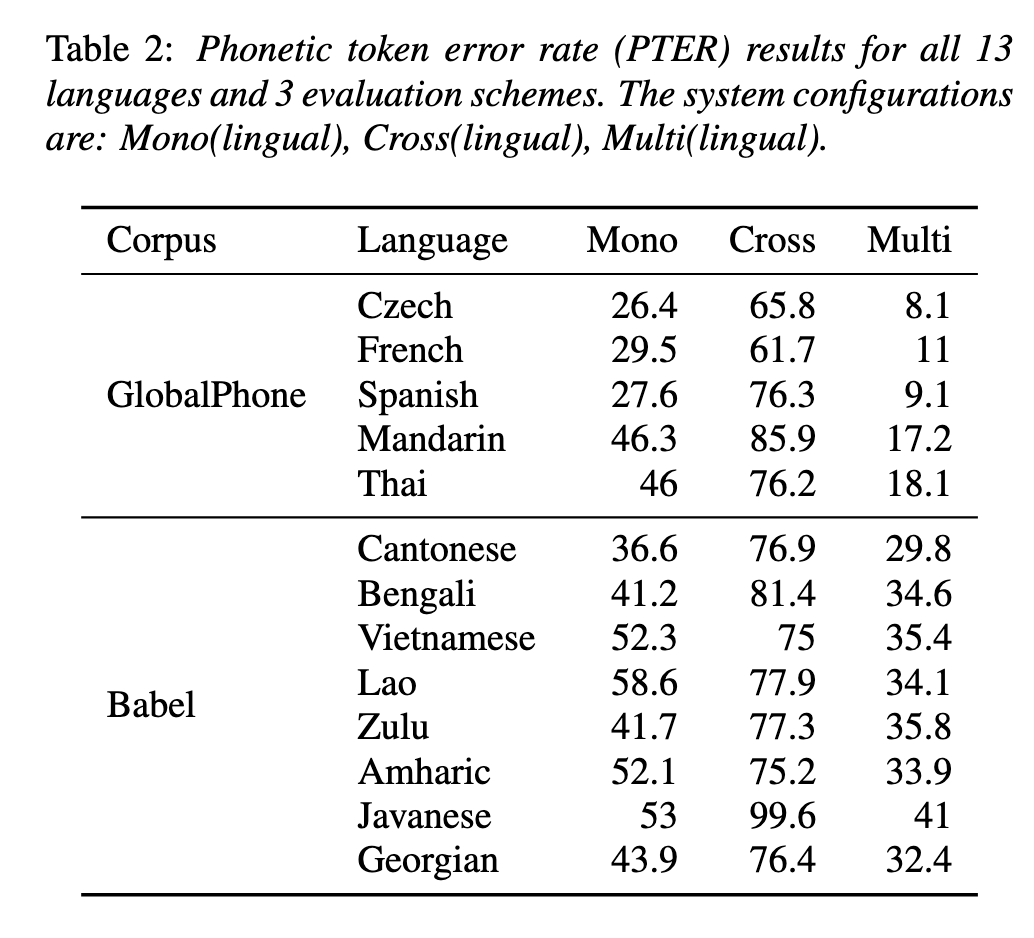
This will create multiple monolingual, multi-lingual and cross-lingual end-to-end automatic speech recognition systems in different languages and about 20 experiments from the paper "That Sounds Familiar: an Analysis of Phonetic Representations Transfer Across Languages."
Working for a better future
Dialog acts: a new library
Code can be found here.
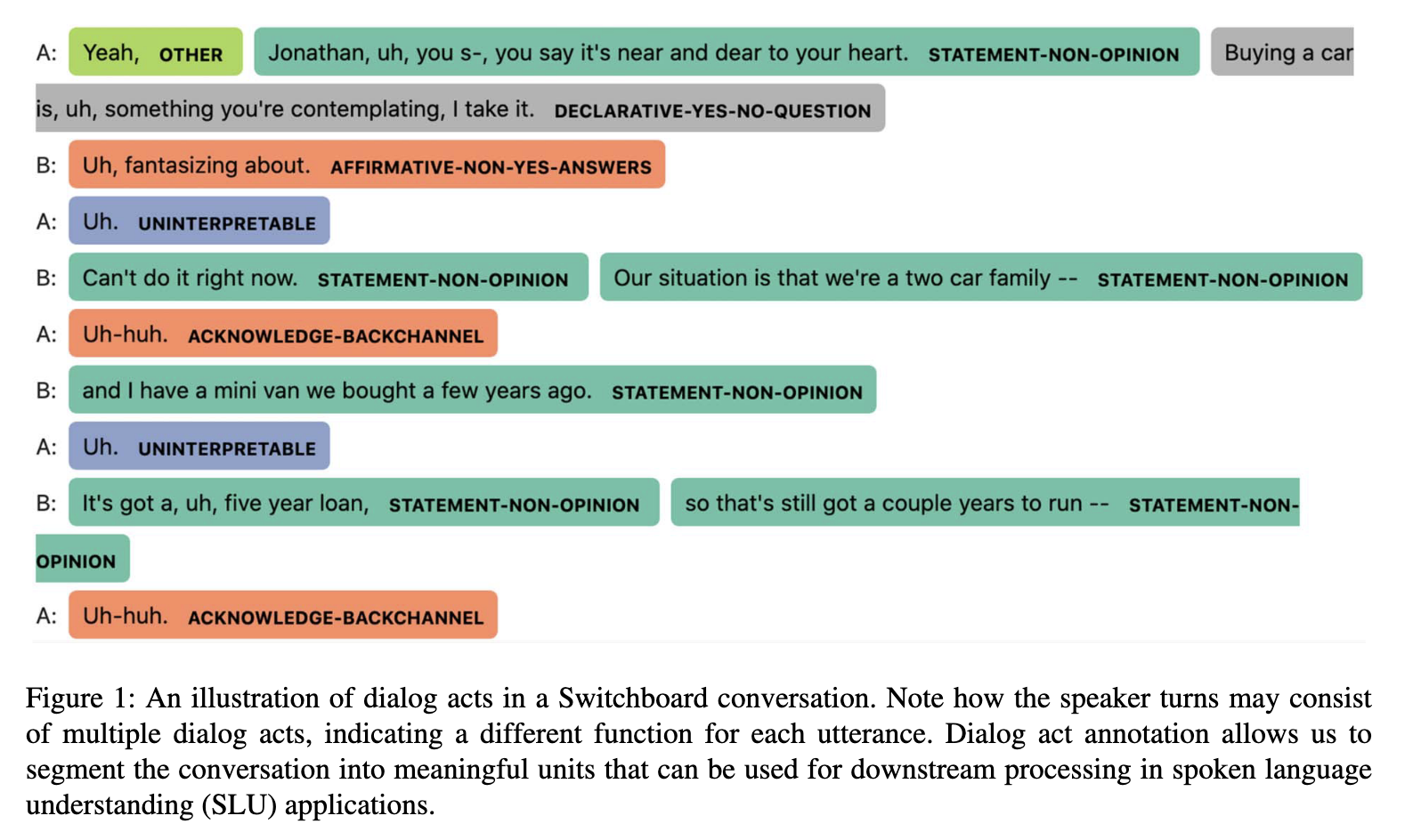
A new library to work with dialog acts. This code is described in the paper "What Helps Transformers Recognize Conversational Structure? Importance of Context, Punctuation, and Labels in Dialog Act Recognition."
Working for a better future
Align-Denoise: Single-Pass Non-Autoregressive Speech Recognition
Code can be found here.
Deep autoregressive models start to become comparable or superior to the conventional systems for automatic speech recognition. However, for the inference computation, they still suffer from inference speed issue due to their token-by-token decoding characteristic. Non-autoregressive models greatly improve decoding speed by supporting decoding within a constant number of iterations. For example, Align-Refine was proposed to improve the performance of the non-autoregressive system by refining the alignment iteratively. In this work, we propose a new perspective to connect Align-Refine and denoising autoencoder. We introduce a novel noisy distribution to sample the alignment directly instead of obtaining it from the decoder output. The experimental results reveal that the proposed Align-Denoise speeds up both training and inference with performance improvement up to 5% relatively using single-pass decoding.
This code is described in the paper "Align-Denoise: Single-Pass Non-Autoregressive Speech Recognition."
Working for a better future
Neurovoz: Rasta-PLP coefficients
Data can be found here.
This repository contains the Rasta-PLP features of six different speech recordings (sentences) from Neurovoz corpus (47 parkinsonian and 32 control speakers whose mother tongue is Spanish Castillian.)
This data is described in the paper "Phonetic relevance and phonemic grouping of speech in the automatic detection of Parkinson’s Disease."
Working for a better future
Earnings 21
Data can be found here.
The Earnings 21 dataset ( also referred to as earnings21 ) is a 39-hour corpus of earnings calls containing entity dense speech from nine different financial sectors. This corpus is intended to benchmark automatic speech recognition (ASR) systems in the wild with special attention towards named entity recognition (NER). This code is described in the paper "Earnings-21: A Practical Benchmark for ASR in the Wild."
Working for a better future
