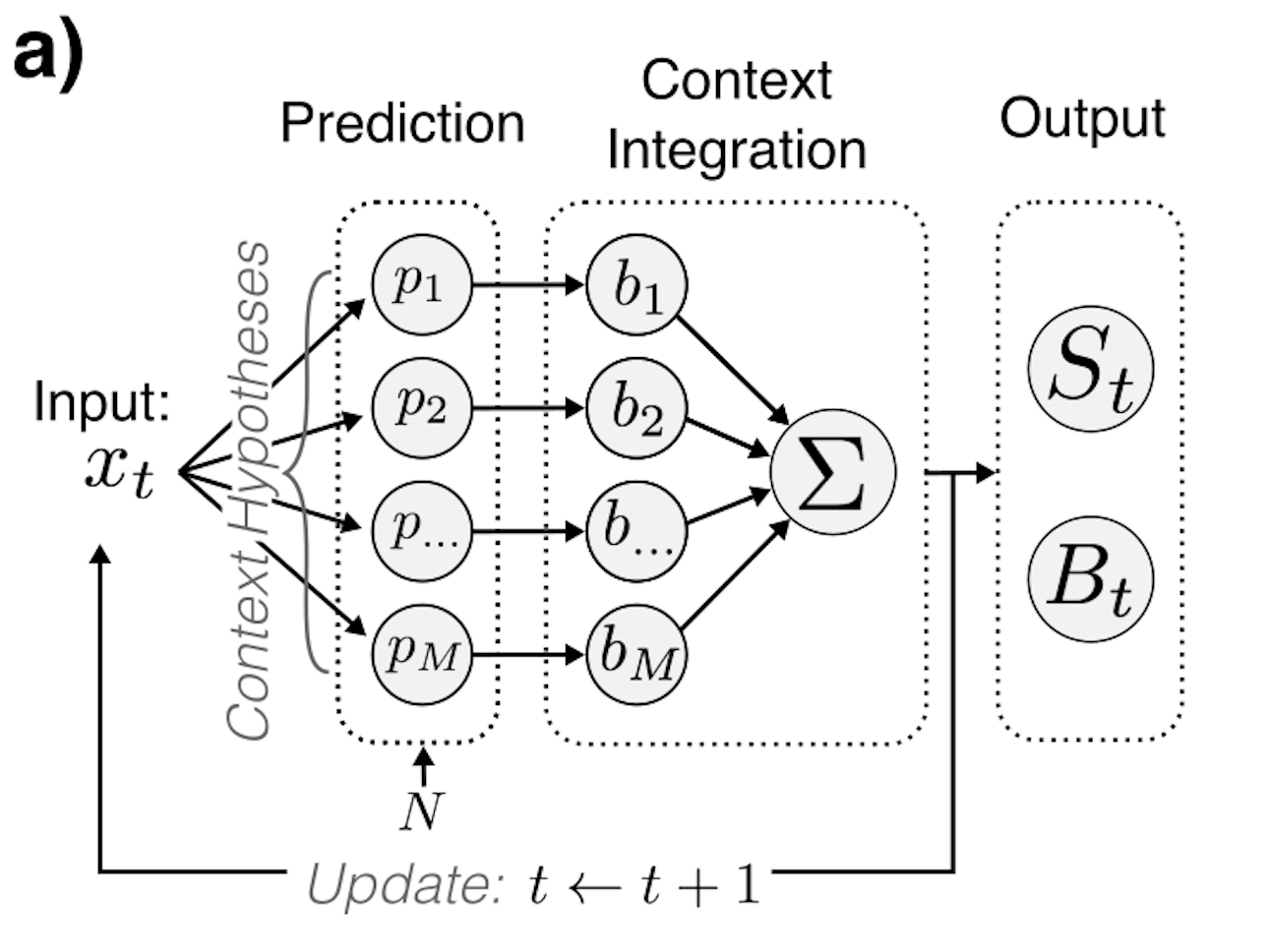
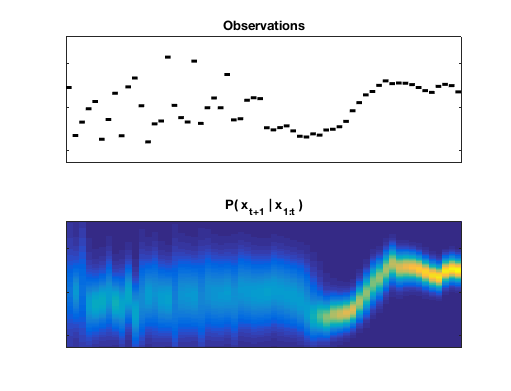
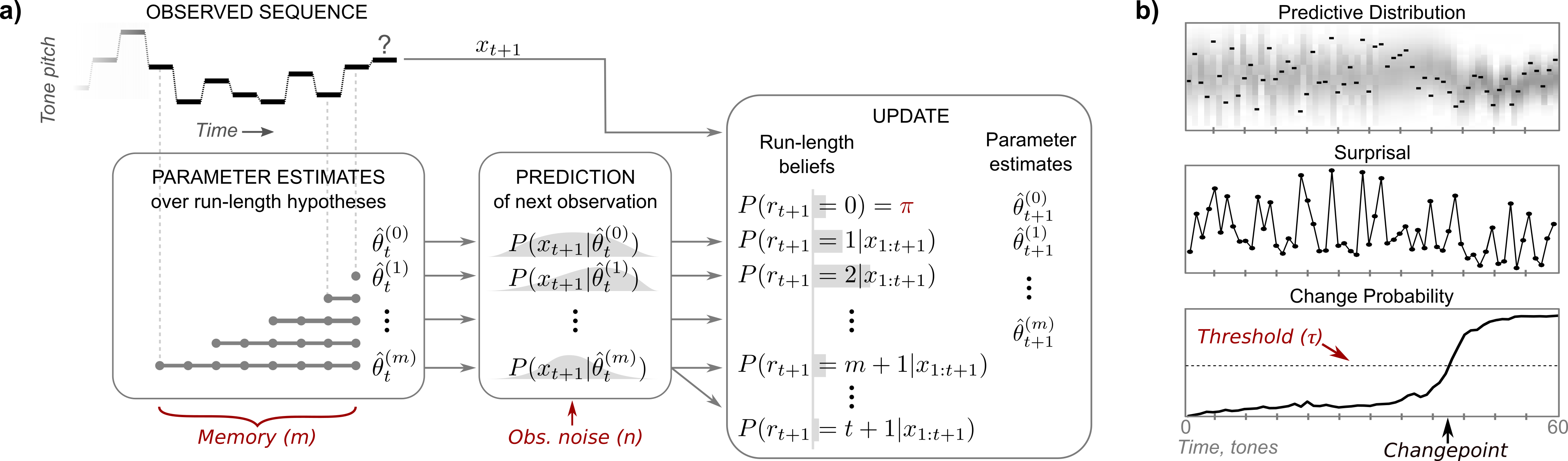
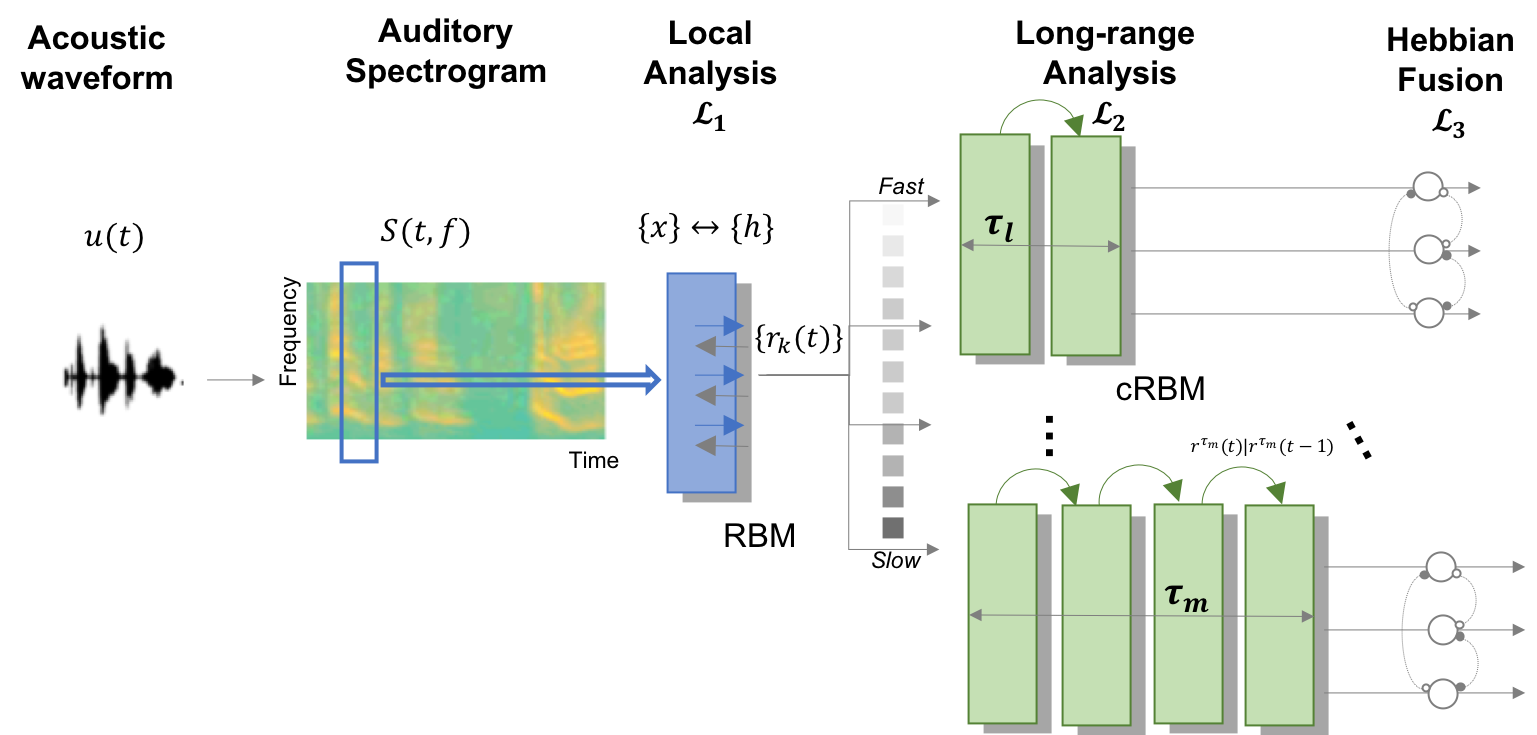
The D-REX model v2 is designed for exploring the computational mechanisms in the brain involved in statistical regularity extraction from dynamic sounds along multiple features. Utilizing a Bayesian inference framework for performing sequential prediction in the presence of unknown changepoints, this model can be used to explore how statistical properties are collected along multiple perceptual dimensions (e.g., pitch, timbre, spatial location). Perceptual parameters can be used to fit the model to individual behavior.
Download includes README, model code, and a helper function for displaying model output --- all code is in MATLAB.
Please enter the information below to download: